Ying Shen
Ying Shen
Home
Publications
Experience
Light
Dark
Automatic
1
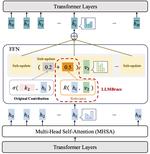
LLM Braces: Straightening Out LLM Predictions with Relevant Sub-Updates
Recent findings reveal that much of the knowledge in a Transformer-based Large Language Model (LLM) is encoded in its feed-forward …
Ying Shen
,
Lifu Huang
PDF
Cite
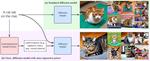
Kaleido Diffusion: Improving Conditional Diffusion Models with Autoregressive Latent Modeling
Diffusion models have emerged as a powerful tool for generating high-quality images from textual descriptions. Despite their successes, …
Jiatao Gu
,
Ying Shen
,
Shuangfei Zhai
,
Yizhe Zhang
,
Navdeep Jaitly
,
Joshua M. Susskind
PDF
Cite
Poster
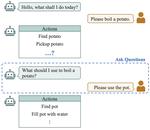
Learning by Asking for Embodied Visual Navigation and Task Completion
The research community has shown increasing interest in designing intelligent embodied agents that can assist humans in accomplishing …
Ying Shen
,
Daniel Bis
,
Cynthia Lu
,
Ismini Lourentzou
PDF
Cite
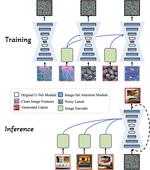
Many-to-many Image Generation with Auto-regressive Diffusion Models
Recent advancements in image generation have made significant progress, yet existing models present limitations in perceiving and …
Ying Shen
,
Yizhe Zhang
,
Shuangfei Zhai
,
Lifu Huang
,
Joshua M. Susskind
,
Jiatao Gu
PDF
Cite
Poster
InternalInspector I2: Robust Confidence Estimation in LLMs through Internal States
Despite their vast capabilities, Large Language Models (LLMs) often struggle with generating reliable outputs, frequently producing …
Mohammad Beigi
,
Ying Shen
,
Runing Yang
,
Zihao Lin
,
Qifan Wang
,
Ankith Mohan
,
Jianfeng He
,
Ming Jin
,
Chang-Tien Lu
,
Lifu Huang
PDF
Cite
Multimodal Instruction Tuning with Conditional Mixture of LoRA
Multimodal Large Language Models (MLLMs) have demonstrated remarkable proficiency in diverse tasks across different domains, with an …
Ying Shen
,
Zhiyang Xu
,
Qifan Wang
,
Yu Cheng
,
Wenpeng Yin
,
Lifu Huang
PDF
Cite
Poster
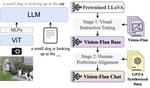
Vision-Flan: Scaling Human-Labeled Tasks in Visual Instruction Tuning
Despite vision-language models' (VLMs) remarkable capabilities as versatile visual assistants, two substantial challenges persist …
Zhiyang Xu
,
Chao Feng
,
Rulin Shao
,
Trevor Ashby
,
Ying Shen
,
Di Jin
,
Yu Cheng
,
Qifan Wang
,
Lifu Huang
PDF
Cite
Project
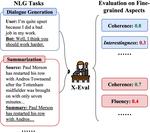
X-EVAL: Generalizable Multi-aspect Text Evaluation via Augmented Instruction Tuning with Auxiliary Evaluation Aspects
Natural Language Generation (NLG) typically involves evaluating the generated text in various aspects (e.g., consistency and …
Minqian Liu
,
Ying Shen
,
Zhiyang Xu
,
Yixin Cao
,
Eunah Cho
,
Vaibhav Kumar
,
Reza Ghanadan
,
Lifu Huang
PDF
Cite
MULTISCRIPT: Multimodal Script Learning for Supporting Open Domain Everyday Tasks
Automatically generating scripts (i.e. sequences of key steps described in text) from video demonstrations and reasoning about the …
Jingyuan Qi
,
Minqian Liu
,
Ying Shen
,
Zhiyang Xu
,
Lifu Huang
PDF
Cite
MULTIINSTRUCT: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning
Instruction tuning, a new learning paradigm that fine-tunes pre-trained language models on tasks specified through instructions, has …
Zhiyang Xu
,
Ying Shen
,
Lifu Huang
PDF
Cite
Code
Poster
Slides
»
Cite
×